This project is now deprecated, consider this archived.
I built SmiteStats.com as I regularly play Smite game with friends. The initial aim was to create a clan based smite stats site just for fun. However it has evolved into quite the project and stores around 4GB of player data including over 5,400,000 match records.
Smite stats relies on the official Hi-Rez Smite, Paladins and Realm Developer API (more details can be found here). The API provides a source for all player and match data. Consequently if the API became unavailable then the site would cease to provide real time data. In that case it would be more of an archive of smite stats data.
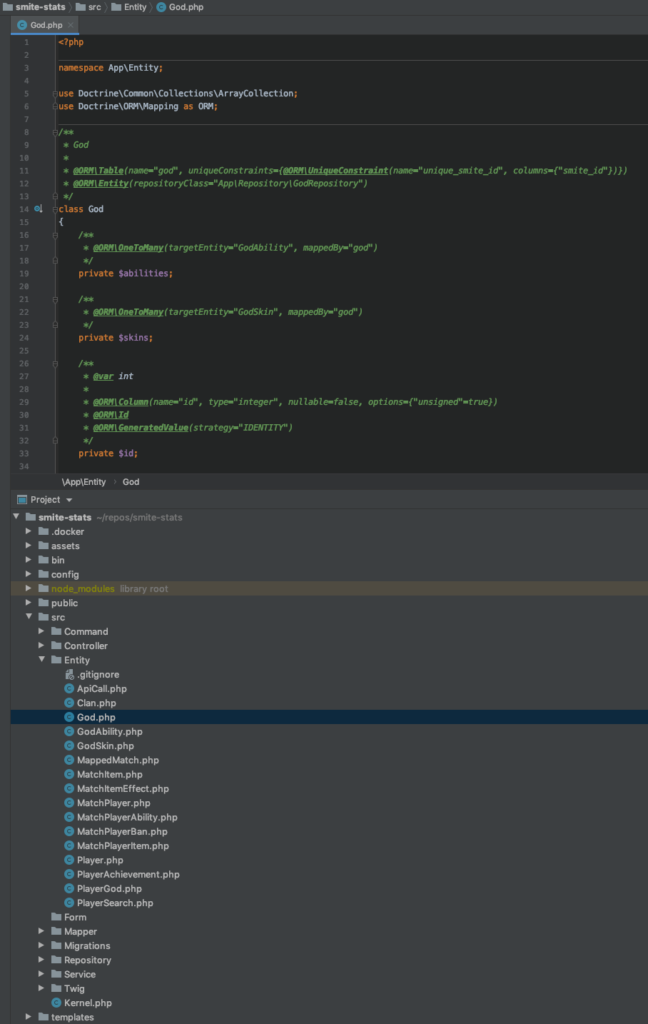
I set the site up using Symfony 5 and a large set of custom entities that model the incoming API data. A mapping class then formats this raw json into an entity prior to persisting to the database with Doctrine.
Minimising API calls
The API has a daily usage limit, Hi-Rez will increase the limits over time if you speak to them and demo a suitable use case. If you limit the amount of calls you make to the API then there’s no reason to do this. For instance this site will cache all API responses with as long a cache TTL as possible. When generating the latest players for a match the site queries the matches endpoint. It then checks if those matches are in the database and stores them if not. Using a matches_updated property on the player entity this is set to the current datetime. The recent matches API query only happens again after fifteen minutes have elapsed. This is particularly helpful to avoid high API usage when a search engine bot crawls the site.
Currently the site is using Redis to cache in memory in the server. It has a suitable memory allocation with a cache eviction policy set to allkeys-lru. This Redis policy means old cache entries are removed to free up space for new entries. For this site this policy works well as the cache items are disposable.
Architecture
The site uses source control via Github and the repository is private with separate branches per feature.
For the server it uses a suitable AWS EC2 instance combined with Elastic Storage to accommodate for data storage needs. I have found EC2 paired with Route 53 for DNS zone management very suitable for small projects.
One limit of the current setup is the lack of automated deployments. A deploy at the moment consists of a PR merge to master. Followed by a cache clear and yarn install. In the future this process will improve with the implementation of Jenkins jobs and/or Ansible playbooks.
Monitoring
To monitor the system I have setup AWS CloudWatch. This integrates well with EC2 and effectively syncs the logs and custom metrics as required.
One of the most useful features is the ability to almost near time remotely monitor the storage, CPU and memory levels. Alarms and events can then be trigger to warn of production critical issues. It also comes in handy when debugging historical events as you have a full system usage graph history.
Database
Currently the MySQL database is local on the EC2 instance. This has issues because it doesn’t scale as well. Ideally the MySQL database would be remote on another instance with it’s own environment configuration. An even better solution would be to use Docker containers but on initial setup I wasn’t too familiar with that approach combined with EC2. Something to improve and blog about in the future.
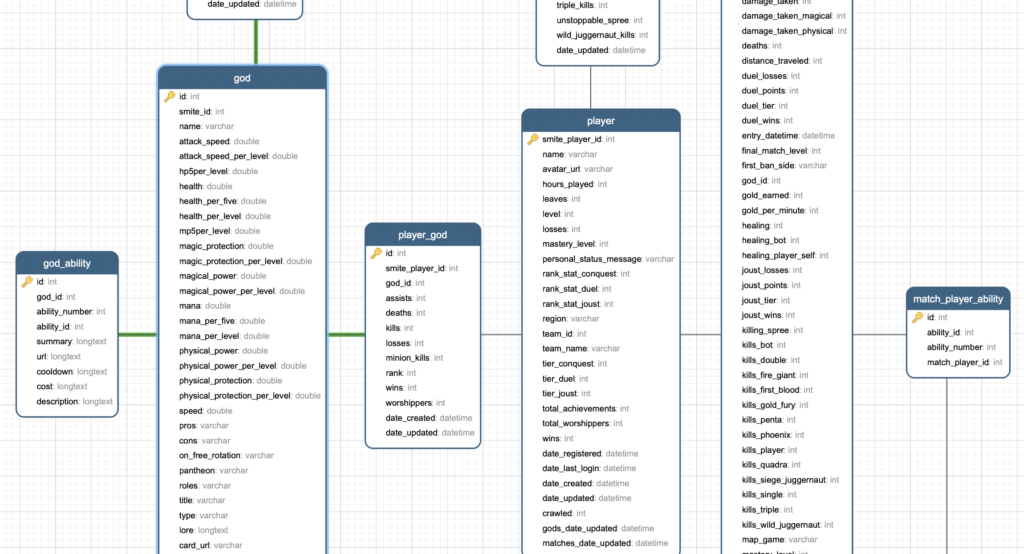
The database is has version control via the aforementioned Symfony Entities combined with Doctrine migrations. I find this to be a very effective approach to easily storing and managing entities.
In total the database has 16 tables, these are all fully relational with correct data types, indexes and foreign keys. As of writing the largest table, the match_player_item has ~28,590,000 entries. This table alone consists of around 982MB data around what items a player made use of in a match. However size wise the match_player is the largest and ~5,467,000 entries store 2.1GB. Some may argue this is too large for one table but the data maps 1-1 with the match player API response. To separate this data further would only increase the complexity for the mappers to little gain.
Front-end
The front-end of the site is of a minimal design (design creation has never been my strong point). Bootstrap 4 is in use for the markup and design style. I wrote some custom css to give it more of a Smite feel. Chart.Js is in use for the graphs but they could do with more customisation. The Smite build generator tool makes use of AngularJS as it requires more dynamic data. However as AngularJS has been deprecated React may be a possible to replace that at some point. Lastly webpack encore is in use with yarn to manage and install the dependencies.
Summary
Overall this covers the setup used for the site. There are areas that could do with improvement but I feel the above is a solid setup for a relatively small website.
So go and install Smite via Steam, Xbox One or PS4 and join us in the game! You’ll then have a perfect platform to check your playing stats to see if you’re any good.
I also welcome feedback on the site and suggestions for improvement. The whole purpose was to create a communal Smite stats site that benefits all those who make use of it.
Due to the sheer cost of running this service I have decided to deprecate the site. The code is now open source on Github so please take a look!